

Executive Summary
Our research uncovered a fundamental flaw in the AI supply chain that allows attackers to gain Remote Code Execution (RCE) and additional capabilities on major platforms like Microsoft’s Azure AI Foundry, Google’s Vertex AI and thousands of open-source projects. We refer to this issue as Model Namespace Reuse.
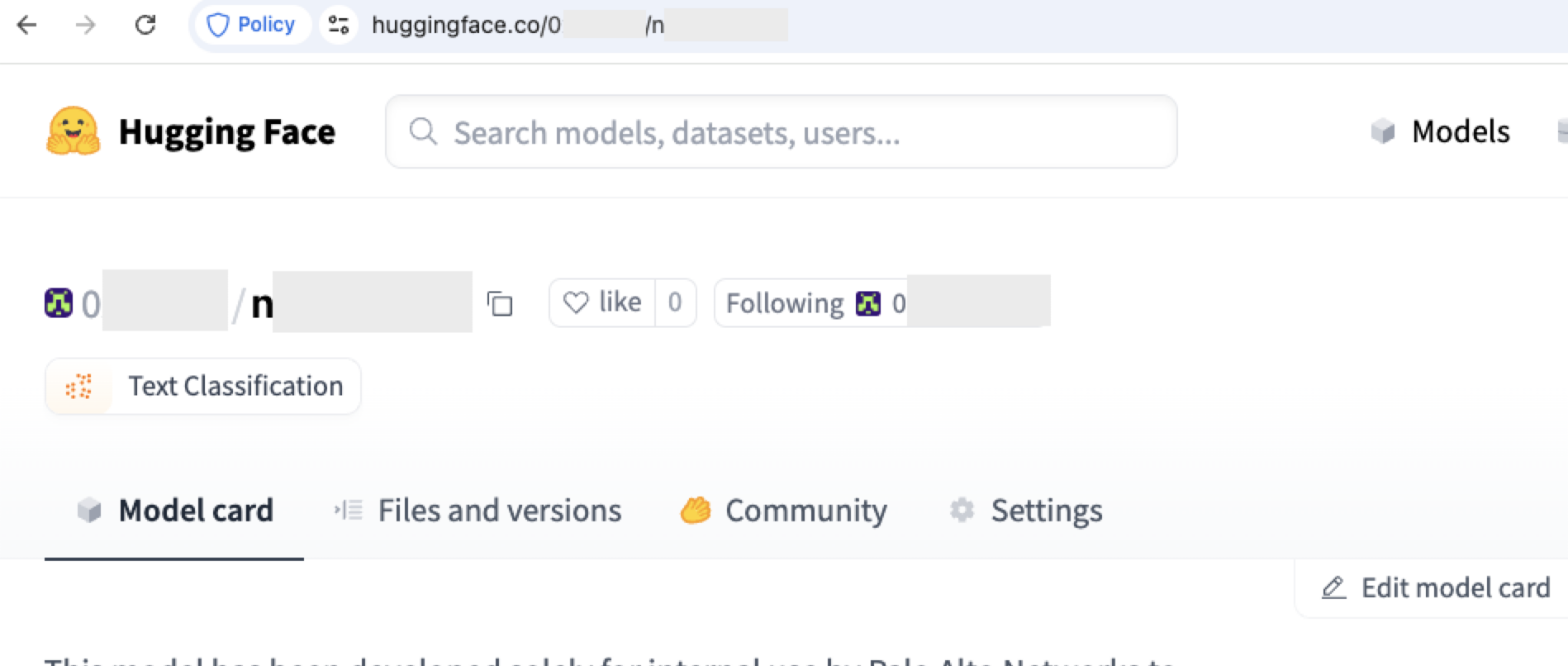
Hugging Face is a platform that enables AI developers to build, share and deploy models and datasets. On that platform, namespaces are the identifiers of models, which are Git repositories that are stored on the Hugging Face hub. Hugging Face models contain configurations, weights, code and information to enable developers to use the models.
Model Namespace Reuse occurs when cloud provider model catalogs or code retrieve a deleted or transferred model by name. By re-registering an abandoned namespace and recreating its original path, malicious actors can target pipelines that deploy models based solely on their name. This potentially allows attackers to deploy malicious models and gain code execution capabilities, among other impacts.
While we have responsibly disclosed this to Google, Microsoft and Hugging Face, the core issue remains a threat to any organization that pulls models by name alone. This discovery proves that trusting models based solely on their names is insufficient and necessitates a critical reevaluation of security in the entire AI ecosystem.
Organizations can gain help assessing cloud security posture through the Unit 42 Cloud Security Assessment.
The Unit 42 AI Security Assessment can assist organizations with empowering safe AI use and development.
If you think you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response team.
Explaining Model Namespace Reuse
Understanding how Hugging Face organizes and identifies models is crucial to understanding the model namespace reuse technique. The most common resource on their platform is the model. These models are essentially Git repositories that contain model configurations, weights and any additional code or information that developers and researchers might need to use the models effectively.
How Developers Pull Models
For identification and access, developers can reference and pull models using a two-part naming convention: Author/ModelName. In this structure, the Author component represents the Hugging Face user or organization that published the model, while ModelName is the name of the model.
For example, if AIOrg published the model Translator_v1, the model name is AIOrg/Translator_v1. Author names serve as unique identifiers. If an author already exists, a new author with the same name cannot be created.
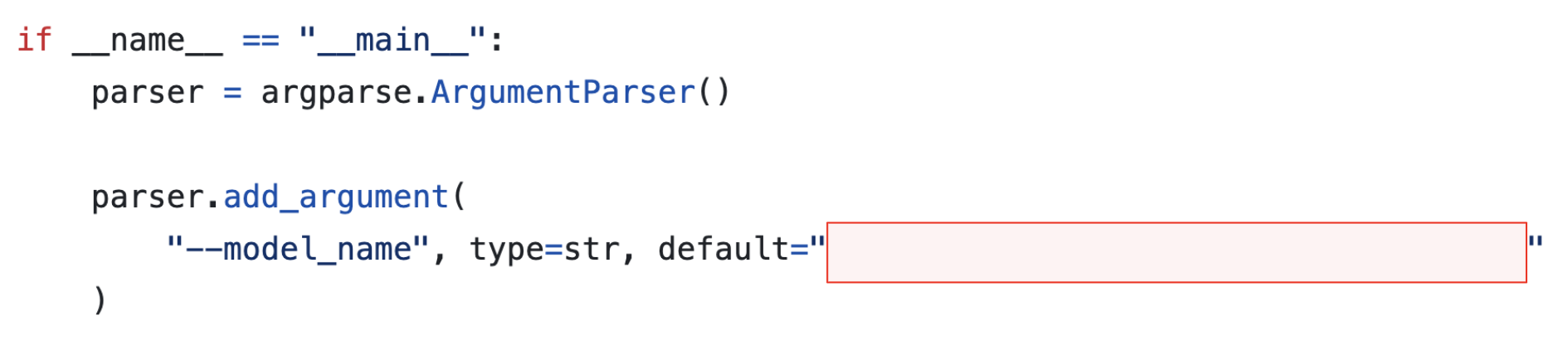
Developers use the Author/ModelName identifier directly in their code across various Hugging Face libraries to fetch and utilize models. For example, developers can use the code shown in Figure 1 to fetch the Translator_v1 model from the commonly used Transformers library.
This hierarchical structure allows for clear attribution and organization. However, in the absence of stringent lifecycle controls over these namespaces, this structure also creates an unexpected attack surface.
The model namespace reuse technique exploits the way that Hugging Face manages Author/ModelName namespaces after an organization or author deletes their own account. Our investigation into this area revealed a critical aspect: Anyone can re-register a deleted namespace.
When a user or organization is deleted from Hugging Face, its unique namespace does not become permanently unavailable. Instead, these identifiers return to a pool of available names, allowing another user to later create an organization with the same name. This reuse process is shown in Case Study 1 – Vertex AI.
Ownership Deletion in Hugging Face
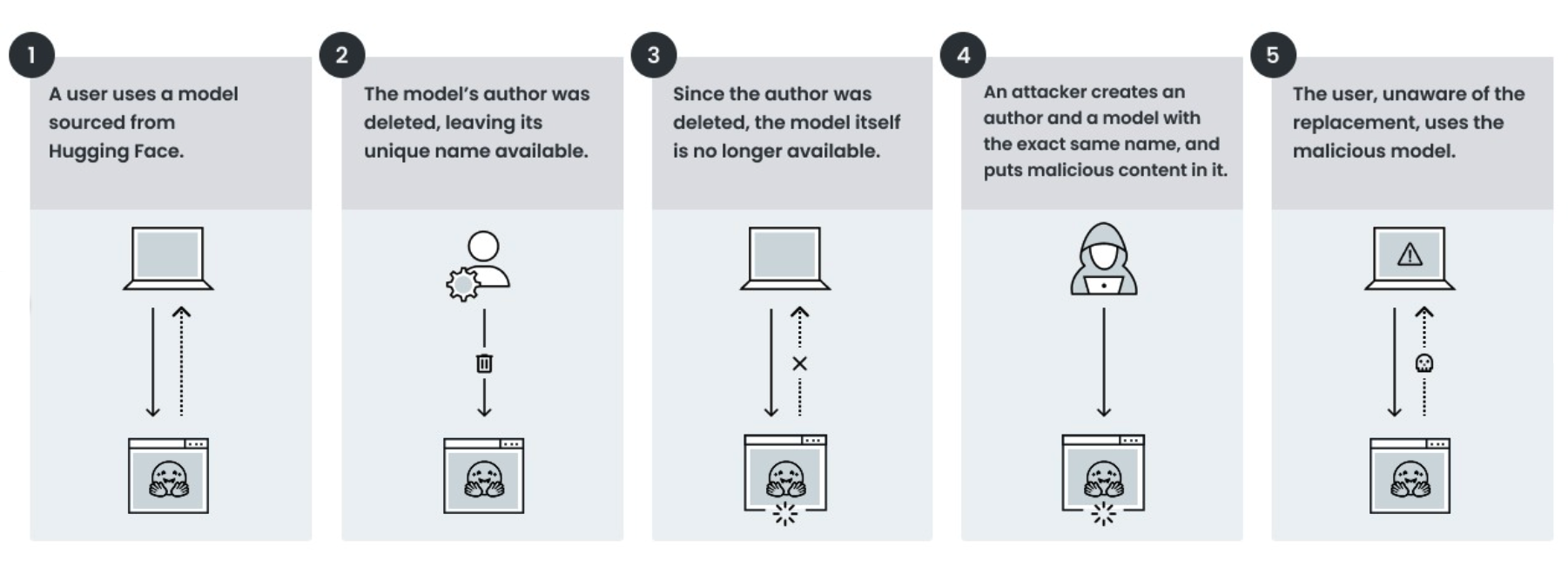
Consider the following fictional scenario of a model that had its author deleted:
The DentalAI organization created the legitimate model toothfAIry. The model can analyze dental images and accurately detect cavities and other tooth abnormalities. Its effectiveness and ease of use made it a favorite among developers, dental researchers and healthcare professionals. Over time, DentalAI/toothfAIry was integrated into diagnostic tools, medical platforms and even open-source health-tech repositories.
At some point, however, developers from DentalAI deleted the organization from Hugging Face. A malicious actor noticed this and took advantage of the situation by recreating the DentalAI organization and uploading a compromised version of the toothfAIry model under the same name.
As a result, all codebases and pipelines still referencing the original model are now at serious risk.
One might assume that as long as a trusted model name continues to function in its code, there is no risk of malicious reuse of that namespace. This is a misconception. Without developers being aware of it, codebases and pipelines might pull and deploy the malicious version. Malicious models could result in a range of unintended outcomes, from incorrect diagnoses to ongoing unauthorized access by an attacker on affected systems.
Figure 2 outlines the steps followed in this fictional scenario.
Another potential attack vector stems from the way Hugging Face manages the transfer of model ownership.
Ownership Transfer in Hugging Face
Hugging Face provides the ability to change the author of a model by transferring ownership from the current owner to another. This transfer results in a new namespace for the model — for example, changing from AIOrg/Translator_v1 to AIOrgNew/Translator_v1. Users can deploy the model using this new namespace. However, the original namespace remains accessible for deployment as well.
When a user submits a request to the old namespace, Hugging Face automatically redirects the user to the new, current namespace. This redirection applies across all access points, including the user interface (UI), REST APIs and common software development kits (SDKs).
This behavior is logical and intentional. Hugging Face aims to ensure that existing pipelines continue functioning smoothly even after a namespace change. However, as shown in the scenario above, if the owner of the original model deleted its organization, the namespace becomes available for re-registration.
If a malicious actor registers the namespace, this breaks the redirection mechanism, causing the compromised model to be prioritized over the legitimate new model.
To explain this fictional scenario, we’ll again draw on dental health.
Dentalligence, another organization, has acquired DentalAI. As part of the acquisition, DentalAI transferred all of its AI models to the Dentalligence organization. Following the transfer, the administrators of DentalAI deleted the original organization from Hugging Face, as it was now fully absorbed into Dentalligence.
All models formerly under DentalAI — such as DentalAI/toothfAIry — became accessible via their new paths, like Dentalligence/toothfAIry. For continuity, Hugging Face maintained redirects from the old namespaces to the new ones, allowing users to access the models without updating their code.
However, a malicious actor noticed that the original DentalAI organization was available. The attacker registered a new organization under that name and uploaded malicious models using the same names as those DentalAI hosted before the acquisition.
Since the original model names remained valid and deployable throughout the transition, users were unaware of the change. They didn’t sense any downtime and did not have to change the model names in their code. For example, making a request to pull the model DentalAI/toothfAIry automatically pulled Dentalligence/toothfAIry. As a result, when the malicious actor inserted their version using the original names, users unknowingly began deploying the malicious versions instead of the trusted models they had originally integrated.
Comparing the Scenarios
Hard-coded reusable model namespaces exist in thousands of open-source projects. These include popular and highly starred repositories, and repositories that belong to prominent organizations in the industry. Additionally, such models pose a threat to users of leading AI platforms.
Table 1 sums up the differences between the two scenarios.
| Ownership Deletion | Ownership Transfer | |
| Cause | The model author was deleted from Hugging Face. | The model was transferred to a new owner, and the old author was deleted from Hugging Face. |
| User Experience | Users will experience downtime, as the model does not exist. | Users will not be affected, as their requests are redirected to the new model. |
| HTTP Status Codes on Model Access | 404 | 307 |
| Identifying Signs | The author of the model is no longer available on Hugging Face. | When attempting to access the model, Hugging Face redirects to a different author. In addition, the old author is no longer available. |
Table 1. Key differences between reusable deleted models and reusable transferred models.
Model Namespace Reuse in Practice
Case Study 1: Vertex AI
Google Vertex AI is a managed machine learning (ML) platform on Google Cloud Platform (GCP). Developers use Vertex AI to build and scale models that integrate with other Google Cloud services.
A key feature of Vertex AI is the Model Garden, a centralized repository of pre-trained models from Google, third parties and the open-source community. Notably, Vertex AI’s Model Garden supports direct deployment of models from Hugging Face. This means users can select a model from Hugging Face and deploy it to Vertex AI in just a few steps, without custom packaging.
Figure 3 displays the deployment of the model distilbert/distilgpt2.
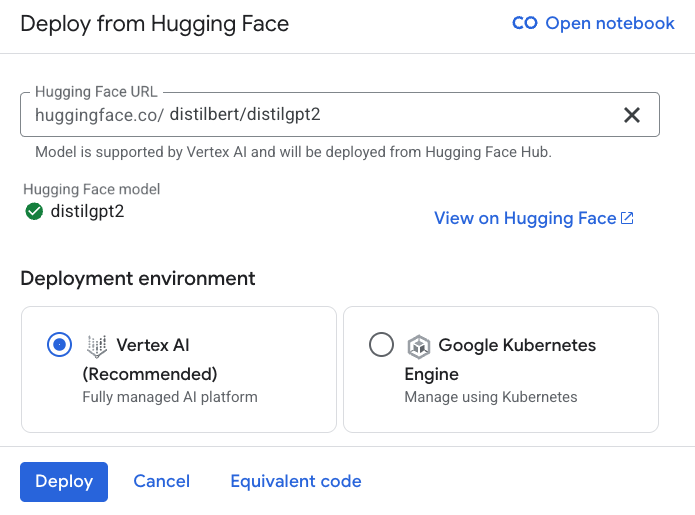
It’s important to note that not all models are immediately deployable via Vertex AI. A green check mark next to the model name signifies that Google has verified that the model can be deployed to Vertex AI.
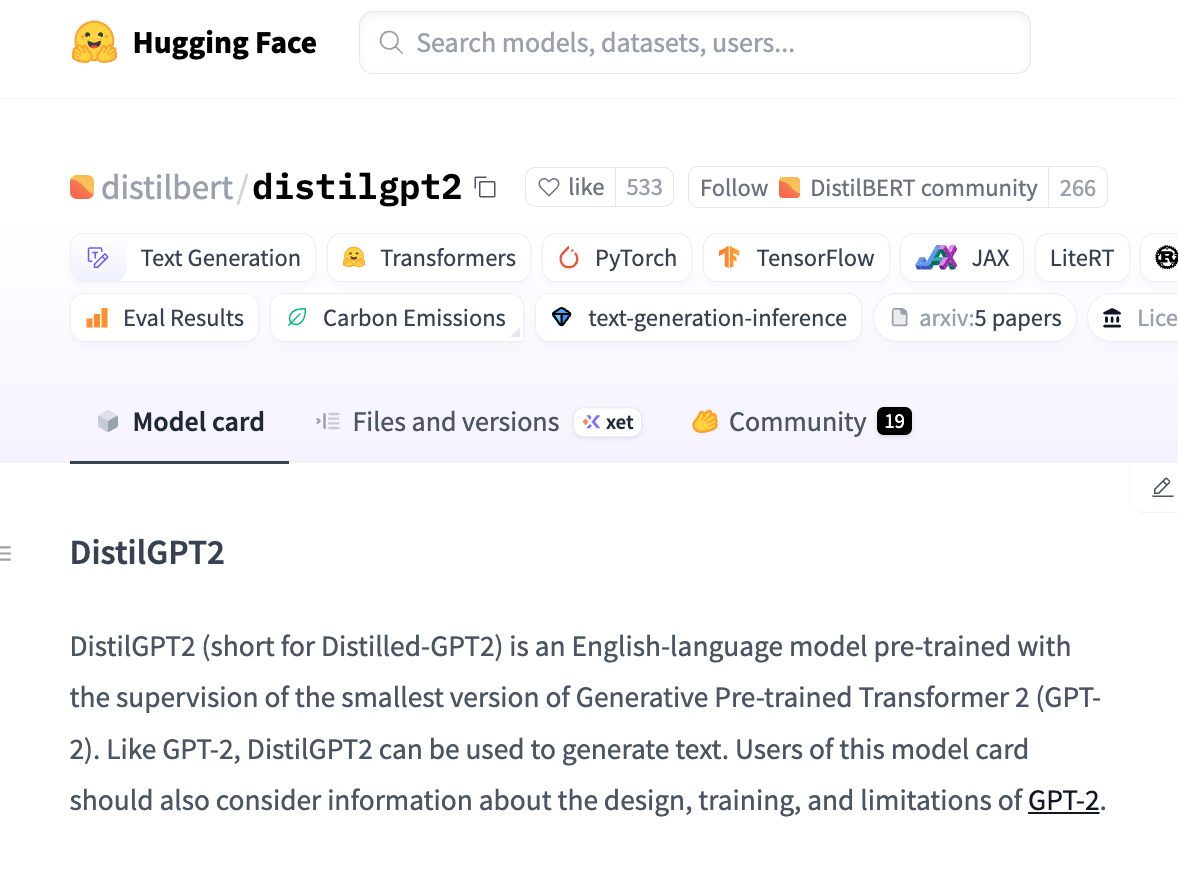
Additionally, the interface provides a convenient link to the model’s card on Hugging Face, allowing users to quickly review documentation, licensing and other key details. Figure 4 shows an example of the model card of the model distilbert/distilgpt2.
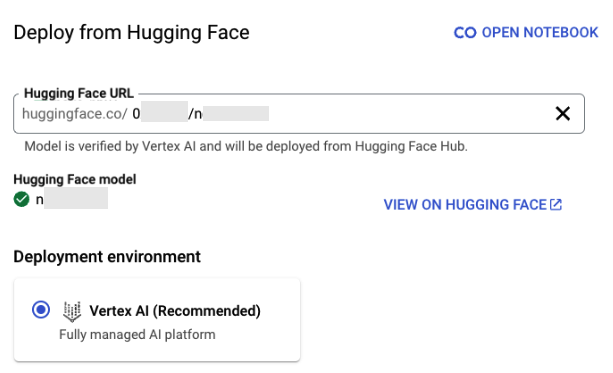
By examining the list of models that Vertex AI offers for direct deployment from Hugging Face and checking whether their original authors have been deleted, we identified several reusable models. These are models that meet both of the following conditions:
- The model owner has deleted the author organization from Hugging Face
- Vertex AI still lists and verifies the model
Figures 5 and 6 illustrate an example of such a model — one that qualifies for deployment on Vertex AI, despite its author not existing on Hugging Face.
We proceeded to register one of the author namespaces and created a model using the same name within it, as Figure 7 shows.
After performing the takeover, any deployment of the original model will instead result in the deployment of our new model.
To demonstrate the potential impact of such a technique, we embedded a payload in the model that initiates a reverse shell from the machine running the deployment back to our servers. Once Vertex AI deployed the model, we gained access to the underlying infrastructure hosting the model — specifically, the endpoint environment. Figure 8 shows the reverse shell from the endpoint to our controlled machine.

The accessed environment is a dedicated container with a limited scope within the GCP environment. Once we demonstrated this vector, we removed the backdoor from the model’s repository.
Since we reported this issue to Google in February 2025, Google now performs daily scans to identify models that have been orphaned. The scan marks orphaned models as “verification unsuccessful,” preventing them from being deployable to Vertex.
Case Study 2: Azure AI Foundry
Azure AI Foundry is Microsoft’s platform for developing ML and generative AI applications. It provides tools for the different stages of the AI lifecycle, including data ingestion, model training, deployment and monitoring.
At the core of Azure AI Studio is its Model Catalog — a hub featuring foundation models from Microsoft, open-source contributors and commercial vendors. The catalog in Azure AI Foundry allows users to deploy and customize models on the platform. Figure 9 shows that the catalog features many models sourced from Hugging Face.
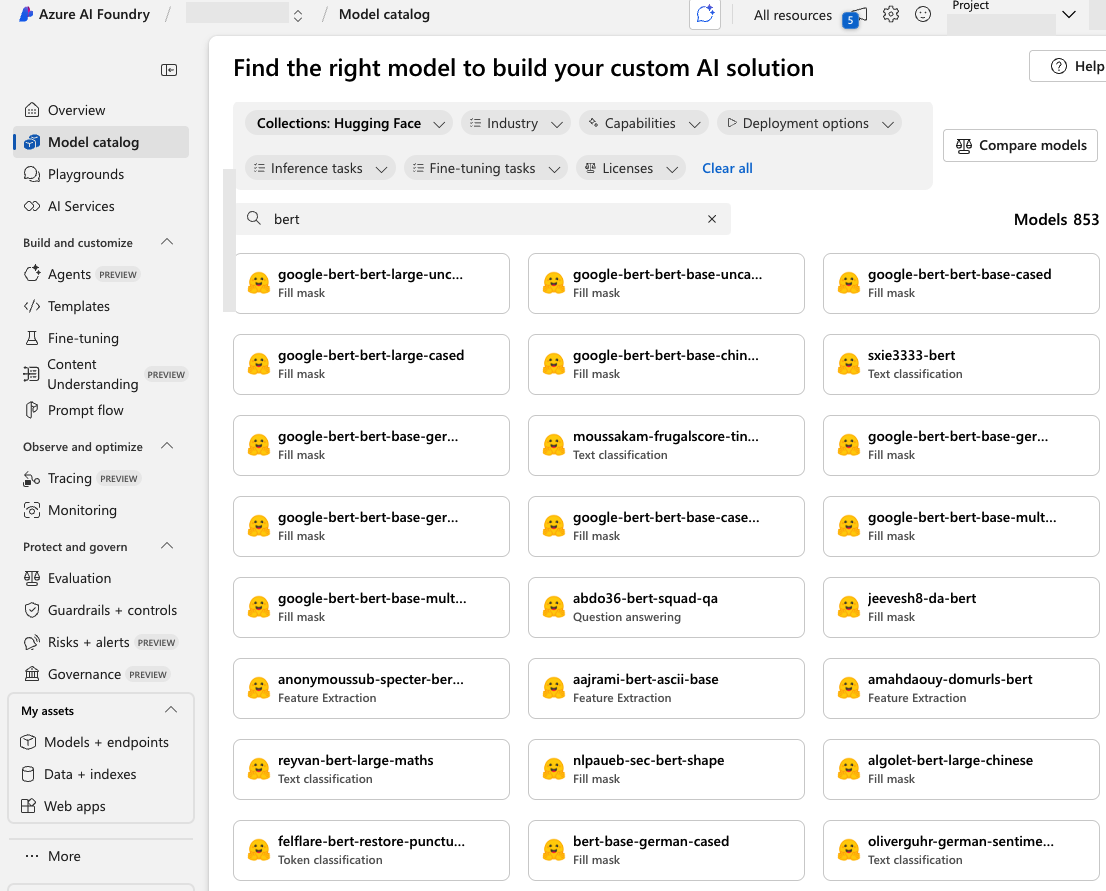
We reviewed the list of models available in Azure AI Foundry and focused on those sourced from Hugging Face. For each model, we checked whether its original author account had been deleted. Once again, we identified several reusable models — models whose author namespaces were no longer claimed but are still available for deployment.
To demonstrate the risk, we registered one of these unclaimed author names on Hugging Face and uploaded a model embedded with a reverse shell. Upon deployment, the reverse shell executed successfully, granting us access to the underlying endpoint, as Figure 10 shows.
By exploiting this attack vector, we obtained permissions that corresponded to those of the Azure endpoint. This provided us with an initial access point into the user’s Azure environment. Once we demonstrated this vector, we removed the backdoor from the model’s repository.
Case Study 3: Open-Source Repositories
After observing the impact of model namespace reuse on leading cloud AI services, we conducted an extensive search of open-source repositories. Our aim was to identify projects that referenced Hugging Face models by Author/ModelName identifiers that are available to be reclaimed.
Such projects expose their users to significant security risks. Attackers can take advantage of project dependencies by identifying an available Author/ModelName, registering it and uploading malicious files to it. These files are then likely to be deployed into user environments during the project’s deployment or execution.
We began by searching GitHub for open-source repositories with SDK methods that fetch models from Hugging Face. We then narrowed the search by identifying model names in these repositories. To discover reusable models, we checked each model for whether its author was deleted and could be registered.
This investigation revealed thousands of susceptible repositories, among them several well-known and highly starred projects. These projects include both deleted models and transferred models with the original author removed, causing users to remain unaware of the threat as these projects continue to function normally.
Figures 11 and 12 demonstrate the presence of reusable models and names in popular open-source projects.

Case Study 4: Model Registries Leak Chain
So far, we’ve examined scenarios in which users and developers fetch models directly from Hugging Face. Whether using a managed AI platform or an open-source SDK, many environments use it as a primary source.
However, other model registries — centralized systems that manage the storage, versioning and lifecycle of ML models — also pull models from Hugging Face and offer them to users as part of their available models.
This creates a supply chain risk. If a model registry ingests reusable models from Hugging Face, those models can propagate downstream. As a result, users relying on such registries could be exposed to compromised models without ever directly interacting with Hugging Face.
Take Vertex AI as an example. As discussed earlier, Vertex AI offers seamless integration to deploy and utilize Hugging Face models within the GCP environment. Users can easily fetch a model using the Vertex AI SDK, as Figure 13 shows.

In this scenario, the user obtains the model model_name directly from Vertex AI. However, if this model is sourced from Hugging Face and is available in the Model Catalog, the user might inadvertently access an infected model.
Another Google-owned platform that incorporates Hugging Face as a model source is Kaggle. Kaggle is a well-known hub for data science and ML that provides datasets, notebooks and a collection of pre-trained models. Figure 14 shows that in its Model Catalog, Kaggle offers thousands of Hugging Face-originated models for deployment.
As with the previously discussed model registries, Kaggle also offers several models that are vulnerable to model namespace reuse, posing an immediate risk to their users.
The Challenge of Model Integrity in AI
Keeping track of ML models is a complex and ongoing challenge. Developers constantly update, fine-tune, fork and republish their models. They often do this across multiple platforms and organizations. We observed model namespace reuse opportunities across various parts of these complex, multi-component systems. This is true not only in model deployments, which pose the most immediate and significant risk. We found reusable model references in model cards, documentations, default parameters and example notebooks.
Finding the same model reuse issue in GCP, Azure and many open-source projects highlights one of the most critical and often overlooked aspects of AI and ML security: verifying that the model you’re using is truly the one you think it is. Whether the project pulls a model from a public registry, reuses it from an internal pipeline, or deploys through a managed service, there’s always a risk that someone replaced, tampered with or exploited the redirection of the model.
Models can originate from a variety of registries, not just Hugging Face. The Vertex AI Model Garden, Azure AI Foundry Model Catalog and Kaggle all feature a wide range of models, including many sourced directly from Hugging Face.
This integration, while convenient, introduces risks. Developers who rely on the trusted model catalogs of major cloud AI services could unknowingly deploy malicious models originally hosted on Hugging Face without ever interacting with Hugging Face directly.
To their credit, all of these platforms make significant efforts to secure their model registries. However, as we’ve demonstrated, no system is entirely immune to namespace hijacking or supply chain vulnerabilities. Even with strong safeguards in place, a single overlooked edge case can lead to destructive exploitation.
Ensuring the security of AI tools is not solely the responsibility of platform providers. Developers must also take active steps to secure pipelines and environments.
Practical Steps for a Secure ML Lifecycle
We’ve explored some of the inherent challenges in securing the pipelines that power ML models. From data ingestion to deployment, ensuring integrity at every step is crucial. But the good news is that we’re not powerless in the face of these complexities. There are concrete steps we can take to significantly improve the security and reliability of AI systems. Following are some key practices.
- Version pinning: Using methods such as from_pretrained(“Author/ModelName”) to fetch models can lead to unexpected behavior, stability concerns or even malicious model integration due to automatic fetching of the latest version. A solution for that is to pin the model to a specific commit using the revision parameter. The command from_pretrained(“Author/ModelName”, revision=”abcdef1234567890″) ensures that the model is in an expected state and prevents the model behavior from changing unexpectedly. This helps the developer to guarantee consistent model behavior for debugging and execution.
- Model cloning and controlled storage: For highly sensitive or production environments, we recommend cloning the model repository to a trusted location, such as local storage, internal registry or cloud storage. This approach enables decoupling model loading from any external source, eliminating the risk of upstream changes or connectivity issues. Cloning the model should, of course, only be done after a robust scanning and verification process.
- Scanning for reusable references: Scan model references in code repositories and treat model references like any other dependency subject to policy and review. Scanning should be comprehensive as models can exist in unexpected places, such as default arguments, docstrings and comments. Proactively scanning codebases for model references reduces the risk of supply chain attacks caused by model namespace reuse.
Conclusion: The New Realities of AI Supply Chain Security
We showed how an attacker could reclaim and reuse model identifiers on Hugging Face to execute remote code within popular AI platforms such as Google Vertex AI, Azure AI Foundry and various open-source projects. In both cases, the issue arises because a model’s name alone is not enough to guarantee its integrity or trustworthiness.
We have discussed this issue with the vendors mentioned in this article. Model namespace reuse is a complex problem to solve and its risk still exists. This is not an isolated problem, but a systemic challenge to how the AI community manages and validates shared model integrity. This challenge extends far beyond simple namespace management, forcing us to confront questions about the foundational security of the rapidly evolving AI infrastructure.
Users can improve security with respect to the threats described above by implementing version pinning, cloning model repositories to trusted storage locations and scanning for reusable references.
Organizations can gain help assessing cloud security posture through the Unit 42 Cloud Security Assessment.
The Unit 42 AI Security Assessment can assist organizations with empowering safe AI use and development.
If you think you may have been compromised or have an urgent matter, get in touch with the Unit 42 Incident Response team or call:
- North America: Toll Free: +1 (866) 486-4842 (866.4.UNIT42)
- UK: +44.20.3743.3660
- Europe and Middle East: +31.20.299.3130
- Asia: +65.6983.8730
- Japan: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 000 800 050 45107
Palo Alto Networks has shared these findings with our fellow Cyber Threat Alliance (CTA) members. CTA members use this intelligence to rapidly deploy protections to their customers and to systematically disrupt malicious cyber actors. Learn more about the Cyber Threat Alliance.